Episodio Speciale — Tech Deep Dive
Come abbiamo costruito un assistente AI in produzione
Negli episodi precedenti abbiamo raccontato cosa SofIA è in grado di fare. In questo entriamo dentro: vediamo cosa serve per farla funzionare davvero.
Costruire un sistema basato su AI non significa integrare un modello linguistico. Significa progettare un’architettura che sia affidabile, controllabile, efficiente e utilizzabile in un contesto reale e complesso come un PMS alberghiero.
Questo non è un tutorial.
Vuole raccontare una panoramica delle scelte architetturali che abbiamo fatto per portare un assistente AI agente dentro un prodotto enterprise.
Per chi vuole capire non solo cosa fa SofIA, ma come.

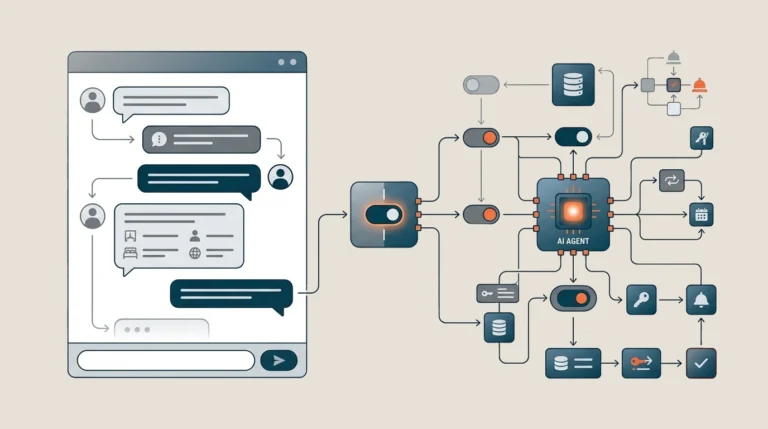
L'AI come orchestratore, non come modello
Il cuore di SofIA non è il modello linguistico, ma l’orchestratore.
È questo componente che trasforma un modello generativo in un sistema operativo per il PMS: gestisce il ciclo di interazione, controlla l’uso degli strumenti, applica limiti di esecuzione per evitare comportamenti anomali e valida le risposte prima che raggiungano l’utente.
Mentre un bot tradizionale riceve un comando e risponde, SofIA esegue un ciclo iterativo noto come Reasoning + Acting (ReAct):
- Analisi/Interpretazione: analizza l’input dell’utente nel contesto hotel.
- Ragionamento (Thought): valuta quali informazioni mancano o quali strumenti servono.
- Esecuzione Tool (Action): chiama strumenti reali (API e funzioni) del PMS.
- Osservazione: riceve e analizza il risultato tecnico restituito dal software e rivaluta la situazione.
- Risposta Finale: traduce il tutto in un linguaggio naturale e utile per l’utente.
Questo approccio permette a SofIA di gestire richieste articolate, come “Cerca una camera per domani e prenota per Mario Rossi”, senza che lo sviluppatore debba prevedere ogni possibile ramificazione del dialogo.
È questo il passaggio da chatbot ad agente.
SofIA Tech Note - Il ciclo ReAct (Reasoning + Acting)
Ogni richiesta attraversa cinque fasi: analisi dell'input nel contesto hotel, ragionamento su cosa manca o cosa serve, esecuzione dello strumento appropriato tra le API e le funzioni del PMS, osservazione del risultato tecnico restituito e produzione della risposta finale in linguaggio naturale.
È questo ciclo che separa un chatbot da un agente.

Oltre il RAG tradizionale: zero database vettoriale
Una delle scelte architetturali più significative riguarda la gestione della documentazione.
L’approccio standard prevede un database vettoriale (embedding, similarity search, chunking): i documenti vengono trasformati in vettori numerici e quando arriva una domanda il sistema cerca i vettori più simili per recuperare il testo rilevante. È un approccio potente, ma richiede infrastruttura dedicata, processi di indicizzazione e una copia aggiornata di tutta la documentazione.
Noi abbiamo scelto una strada diversa, che internamente chiamiamo AI-Driven Dispatching.
Invece di costruire questa infrastruttura, lasciamo che sia direttamente il modello a decidere quale sezione della documentazione interrogare, passando l’identificatore corretto all’endpoint di help già esistente nel prodotto.
Tecnicamente è ancora RAG, ma il retrieval non è basato su similarità statistica: è guidato dal ragionamento del modello.
Il risultato è un’architettura più semplice, senza duplicazione dei dati e con la certezza che le risposte siano sempre allineate alla documentazione ufficiale più aggiornata.
Gestione Risorse: il dilemma tra Cache e compressione
Un modello linguistico non ricorda. La memoria è sempre esterna, e ogni interazione ha un costo che cresce con la dimensione del contesto.
In produzione, gestire questo aspetto in modo efficiente è una delle sfide più concrete.
Abbiamo implementato due strategie divergenti in base alle capacità del provider AI utilizzato.
- Native Context Caching (Gemini): per i modelli che lo supportano, “congeliamo” l’intero contesto (istruzioni + tool + history) in una cache persistente. Questo ci permette di ottenere un risparmio fino al 90% sui token di input, mantenendo la storia completa e accurata.
- Smart History Compression: per i modelli dove il caching non è disponibile o è meno efficiente, SofIA esegue un riassunto automatico quando la chat supera i 20 messaggi. Il riassunto sostituisce i vecchi messaggi, mantenendo intatti solo gli ultimi 6 turni per garantire fluidità.
- La Sfida Tecnologica: riassumere riduce i token totali, ma al contempo “rompe” la cache (perché cambia il testo dell’history).
- Cost Tracking in tempo reale: modulo AI Usage Trackerintegrato che profila (calcolando cache hit e token di ragionamento) e stima in real-time il costo di ogni operazione.
SofIA Tech Note - Il dilemma tra cache e compressione
C'è una tensione strutturale tra le due strategie: riassumere la cronologia riduce i token, ma al tempo stesso invalida la cache, perché il testo dell'history cambia. Trovare il punto di equilibrio tra risparmio e continuità della conversazione è uno dei problemi tecnici più sottili da gestire in un sistema di questo tipo.
Affidabilità: cosa succede quando qualcosa va storto
In produzione il problema non è quanto è valido il modello. È cosa succede quando fallisce.
Un assistente operativo deve essere sempre disponibile. Gli errori tecnici esistono e continueranno a esistere, ma non devono mai raggiungere l’utente sotto forma di crash o messaggi incomprensibili.
Per questo abbiamo costruito due livelli di protezione.
- Fallback Multi-modello: se un modello ad alte prestazioni (es. GPT-4o) ha problemi di latenza o disponibilità, il sistema scala istantaneamente su un modello alternativo (es. GPT-4o-mini) in modo trasparente per l’utente.
- Self-Healing dei prompt: grazie alla traduzione degli errori tecnici in prompt colloquiali, SofIA è in grado di spiegare all’utente l’errore tecnico o il perché un’azione è fallita e suggerire l’alternativa migliore.

Robustezza e comprensione del tempo
I modelli non sempre rispettano i formati richiesti.
E anche concetti apparentemente semplici, come le date, diventano complessi in un sistema reale: il rispetto dei formati e la gestione del tempo.
Sul fronte dei formati (Native Function Calling), a differenza di un semplice chatbot, SofIA non esegue text parsing sperando che funzioni. Sfrutta le Structured Outputs (schema JSON rigorously strictly-typed) forzando letteralmente l’AI a rispondere col formato perfetto. Questo elimina gli errori operativi e sanitizza le chiamate API.
Sul fronte delle date (Normalizzazione Semantica) il problema è più sottile. SofIA include un modulo che interpreta sia linguaggio naturale, espressioni come “tra tre giorni” o “lunedì prossimo“, sia date fisse, normalizzandole con la Work Date del gestionale. Un dettaglio tecnico che, se trascurato, genera errori silenziosi difficili da individuare.
UI/UX: il design come parte del sistema
Il design dell’interfaccia non è un tema estetico.
In un sistema come SofIA è parte integrante dell’esperienza e contribuisce direttamente alla percezione di affidabilità.
Abbiamo curato micro-interazioni come:
lo Streaming & Cursor, la visualizzazione progressiva delle risposte con un cursore lampeggiante di attesa,
il Floating & Docked, un’interfaccia che può essere un FAB (Floating Action Button) o un pannello laterale fisso e ridimensionabile, e
i feedback visivi che indicano in tempo reale quando il sistema è in esecuzione.
Piccoli dettagli che riducono la distanza percepita tra utente e sistema.
Affidabilità operativa
Ogni richiesta elaborata da SofIA vive all’interno di un perimetro di controllo preciso. E per garantire la massima stabilità in produzione, il sistema include strati di controllo a basso livello:
- Timeout controllati: gestione progressiva dei tempi di risposta (come il Time-To-First-Bytee i timeout tra i chunk in streaming) per evitare che un provider lento blocchi l’interfaccia.
- Gestione degli stati: tracciamento rigoroso del ciclo di vita della richiesta.
- Limiti di esecuzione: Applicazione di vincoli hard (MAX_STEPS) e controllo dei loop.
Ogni singola richiesta è confinata in questo perimetro di sicurezza preciso: il risultato è che il sistema non va mai in cortocircuito, nemmeno quando le API rispondono lentamente o il modello tende a divagare.
È questo tipo di controllo a fare la differenza tra un prototipo e un sistema pronto per la produzione.
Un modello non è un prodotto. È un componente.
Il valore di SofIA non nasce dal modello linguistico che utilizza. Nasce da tutto ciò che gli sta attorno: orchestrazione, controllo, gestione degli errori, costo, esperienza utente, affidabilità operativa.
Costruire un sistema AI in produzione non significa aggiungere AI. Significa costruire un sistema che continui a funzionare anche quando l’AI sbaglia.
Perché succede. Sempre.
Ed è lì che si misura davvero la qualità di un’architettura.
SofIA non è un assistente che parla.
È un sistema che agisce.

RICEVI I NOSTRI UPDATE
SofIA è in continua evoluzione o come dicono i tech è under costruction!
Se però vuoi continuare a leggere i prossimi episodi e soprattutto i prossimi sviluppi, iscriviti alla nostra newsletter. Senza spam, solo sostanza.